Vector databases (vector DB) serve as efficient storage and retrieval systems for dense numerical data, representing various types of information like text, images, or media. These databases capitalize on the mathematical concept of vectors, which represent directions in geometric space. By adopting a spatial search approach, vector databases transform the search process from a pattern matching problem to a spatial search problem. This allows queries to retrieve content that is similar to the implied query without explicitly listing all possible options.
The process of converting the original data into vectors is known as embedding. Vectors with similar characteristics and features are positioned closer together in a vector space. For instance, an image of a chicken is situated nearer to the text "chicken" than an image of a banana (Exhibit 1). Vectors act as opaque representations to computers, significantly reducing the necessity to structure data and greatly enhancing data processing efficiency. Although an image or video clip of a cat may not be "natural language" for a computer to comprehend, its mathematical representations are much closer to being computer-native, irrespective of the original modality. This has far-reaching implications for the advancement of generative AI (gen-AI) as vectors expedite the processing of unstructured data, shorten training times, and facilitate application development.
Exhibit 1: Illustration of Vector Embeddings in a Vector Space
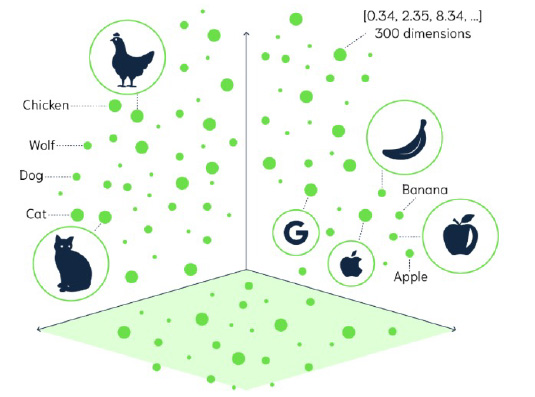
Source: Weaviate
The true power of a vector database lies in its ability to conduct similarity searches, enabling users to find data that is most similar or relevant based on specific semantic or contextual meaning. For example, in an e-commerce website, vector search can assist customers in discovering products similar to a given item, considering their features and other aspects that may be challenging to achieve with conventional search methods. When combined with large language models (LLMs), vector databases become instrumental in facilitating semantic search, video content retrieval, recommendation engines, and other domain-specific applications.
In recent years, vector databases have gained popularity due to the rise of artificial intelligence (AI) and machine learning (ML) applications. Many machine learning models, such as word embeddings and neural network embeddings, produce vector representations of data, allowing seamless integration with vector databases. As a result, these databases have become a fundamental component of modern AI systems, enabling efficient storage, retrieval, and processing of vast amounts of vector-based data.
The market for database management is over $70bn as of 2022 and expected to grow at 10%+ compound annual growth rate (CAGR) over the next several years (Exhibit 2) with emerging database technologies such as vector databases growing faster driven by incremental spend in this category.
Exhibit 2: Expected Growth for Database Management
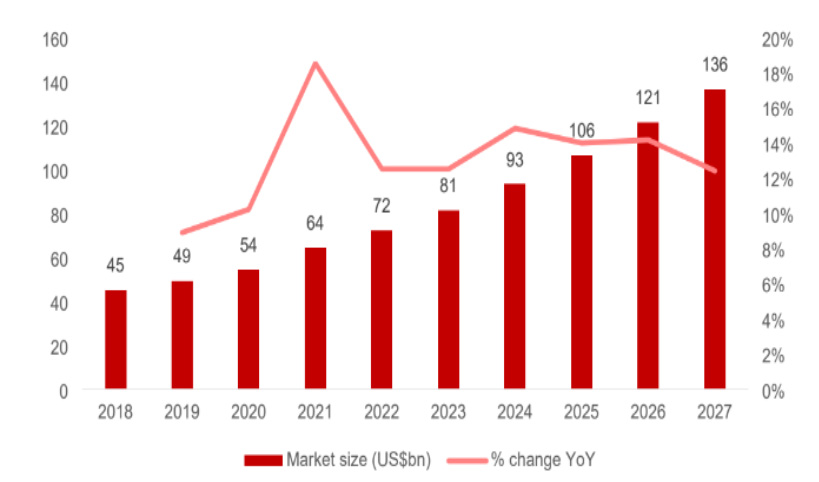
Source: IDC Forecast
Per market forecasts, the vector database market is projected to grow from $1.0 billion in 2021 to reach $2.5 billion by 2025. This substantial growth is expected to be driven by the continuous development, widespread adoption, and increased investment in large language model (LLM) based applications. The recent introduction of ChatGPT in December 2022 is anticipated to play a pivotal role in accelerating this growth. In our portfolios, we have investments in companies that have released vector database modules and are early in the process of monetization. We believe AI/ML adoption in enterprises will necessitate the need for database upgrades driving a multiyear growth trajectory for these companies.
This information is not intended to provide investment advice. Nothing herein should be construed as a solicitation, recommendation or an offer to buy, sell or hold any securities, market sectors, other investments or to adopt any investment strategy or strategies. You should assess your own investment needs based on your individual financial circumstances and investment objectives. This material is not intended to be relied upon as a forecast or research. The opinions expressed are those of Driehaus Capital Management LLC (“Driehaus”) as of July 2023 and are subject to change at any time due to changes in market or economic conditions. The information has not been updated since July 2023 and may not reflect recent market activity. The information and opinions contained in this material are derived from proprietary and non-proprietary sources deemed by Driehaus to be reliable and are not necessarily all inclusive. Driehaus does not guarantee the accuracy or completeness of this information. There is no guarantee that any forecasts made will come to pass. Reliance upon information in this material is at the sole discretion of the reader
Other Commentaries
Data Center
By Ben Olien, CFA
Driehaus Micro Cap Growth Strategy March 2024 Commentary with Attribution
By US Growth Equities Team